Galactic Alchemy I:
Domain Transfer with Generative AI for Hydrodynamical SimulationsSKA research at
Zurich University of Applied Sciences (ZHAW)
Centre for Artificial Intelligence (CAI)
Institute for Business Information Technology (IWI)
Sept 4, 2024
 Philipp Denzel, Yann Billeter, Frank-Peter Schilling, Elena Gavagnin
Philipp Denzel, Yann Billeter, Frank-Peter Schilling, Elena Gavagnin
Domain Transfer with Generative AI for Hydrodynamical SimulationsSKA research at
Zurich University of Applied Sciences (ZHAW)
Centre for Artificial Intelligence (CAI)
Institute for Business Information Technology (IWI)
Zurich University of Applied Sciences (ZHAW)
Institute for Business Information Technology (IWI)
Philipp Denzel, Yann Billeter, Frank-Peter Schilling, Elena Gavagnin
Slides on my website

Outlook
Motivation
- teaching machines to emulate physics is cool!
- benefit for fields like gravitational lensing
- SKA-MID (0.35 GHz - 15 GHz, lower redshifts):
- between 0.04" - 0.70" resolution (with baseline ~ 150km)
- significant substructure in flux distributions
- enable new perspective on star-formation as well as AGN
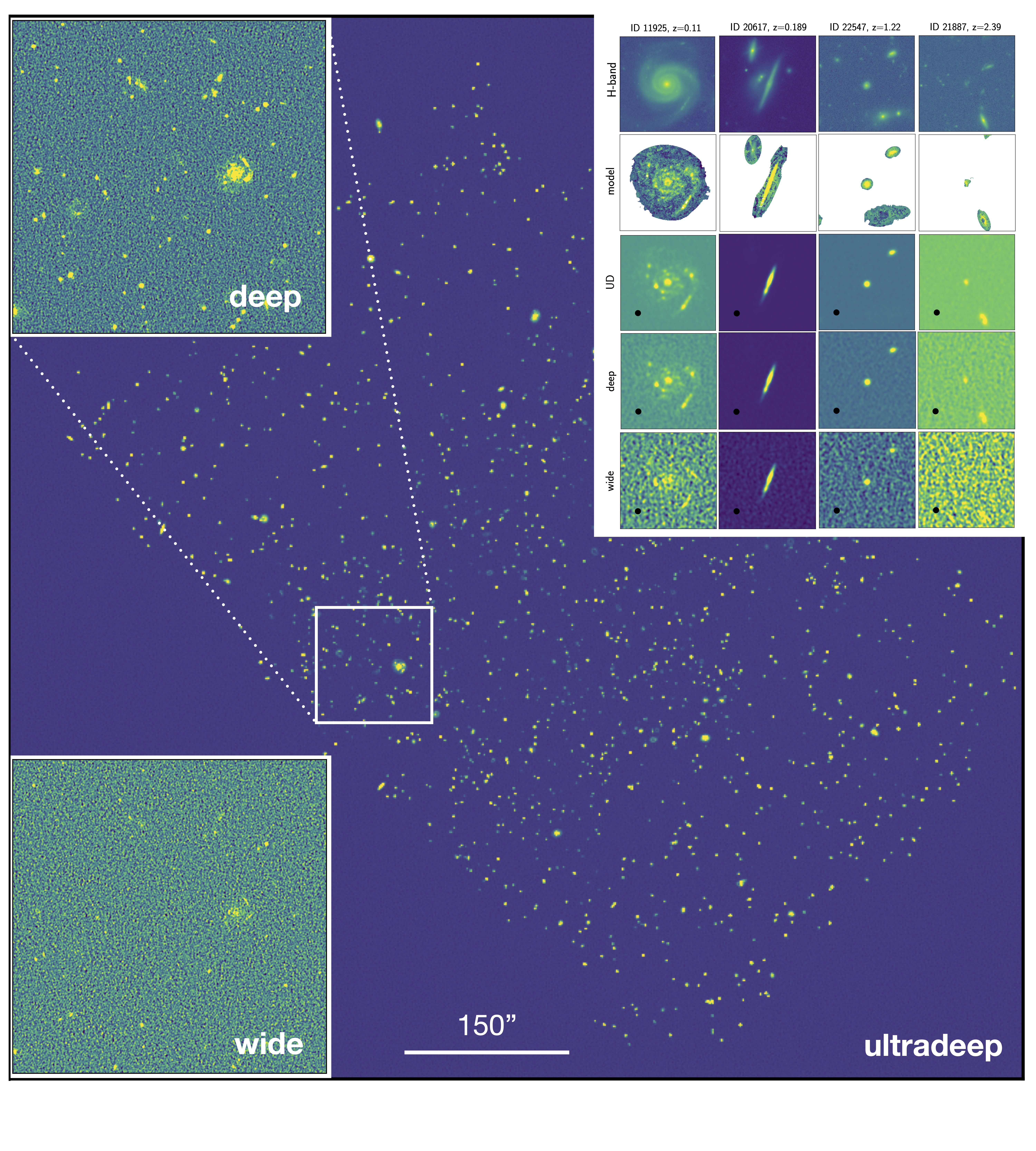
Figure 1: simulation of ∼0.04 deg2 region of GOODS-North by Coogan et al. (2023)
Figure 2: zoom of previous figure Coogan et al. (2023)
The old way of modelling galaxies

Figure 3: Mandelbaum et al. (2014)
What problems come with this
- simple models work for simple galaxies, but we will often see:
- no more blobs, no more Gaussian signals
- not physical models:
- difficult to infer physical properties
- galaxy modelling has to evolve:
- e.g., with data-driven methods
More advanced models
- complex, realistic models
- self-consistent dynamics
- physics: on a wide range of scales
- implicit models:
- what if we want to fit them
to an observation?
- what if we want to fit them
Figure 4: IllustrisTNG simulations
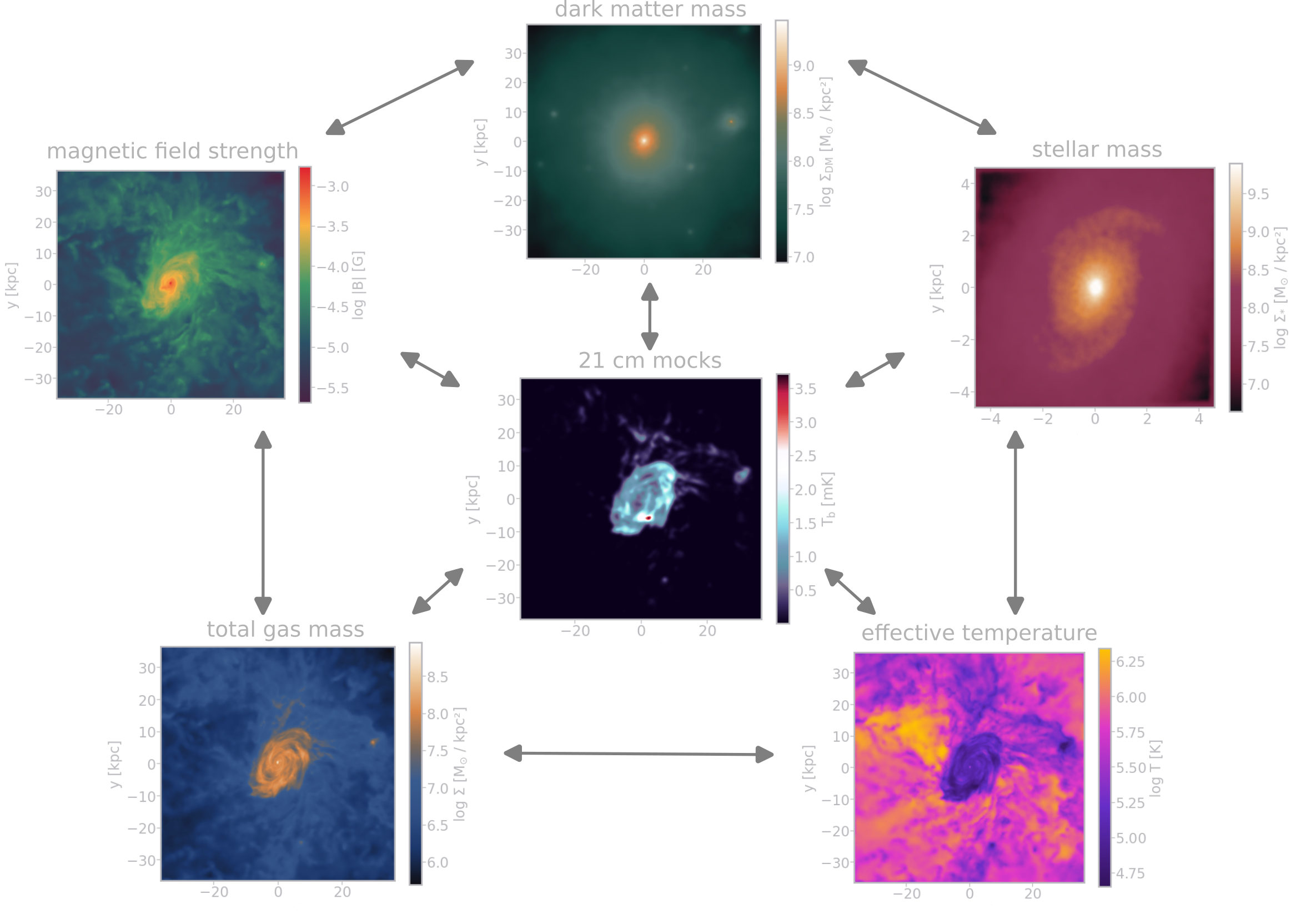
Multi-domain galaxy image dataset
Our goal:
"Infuse deep learning map-to-map translation models
with the physical model from simulations."
- Question: can we infer unseen properties in observations?
Dataset from IllustrisTNG
- projected TNG50-1 galaxies
- 6 domains: dark-matter, stars, gas,
HI, temperature, magnetic field- 21cm mocks following
Villaescusa-Navarro et al. (2018) - Karabo mock upgrade coming soon
- 21cm mocks following
- ∼ 2'000 galaxies, 6 snapshots,
5 rotations in 3D, ∼ 360'000 images - each galaxy \(\ge\) 10'000 particles
- scale: 2 baryonic half-mass radii
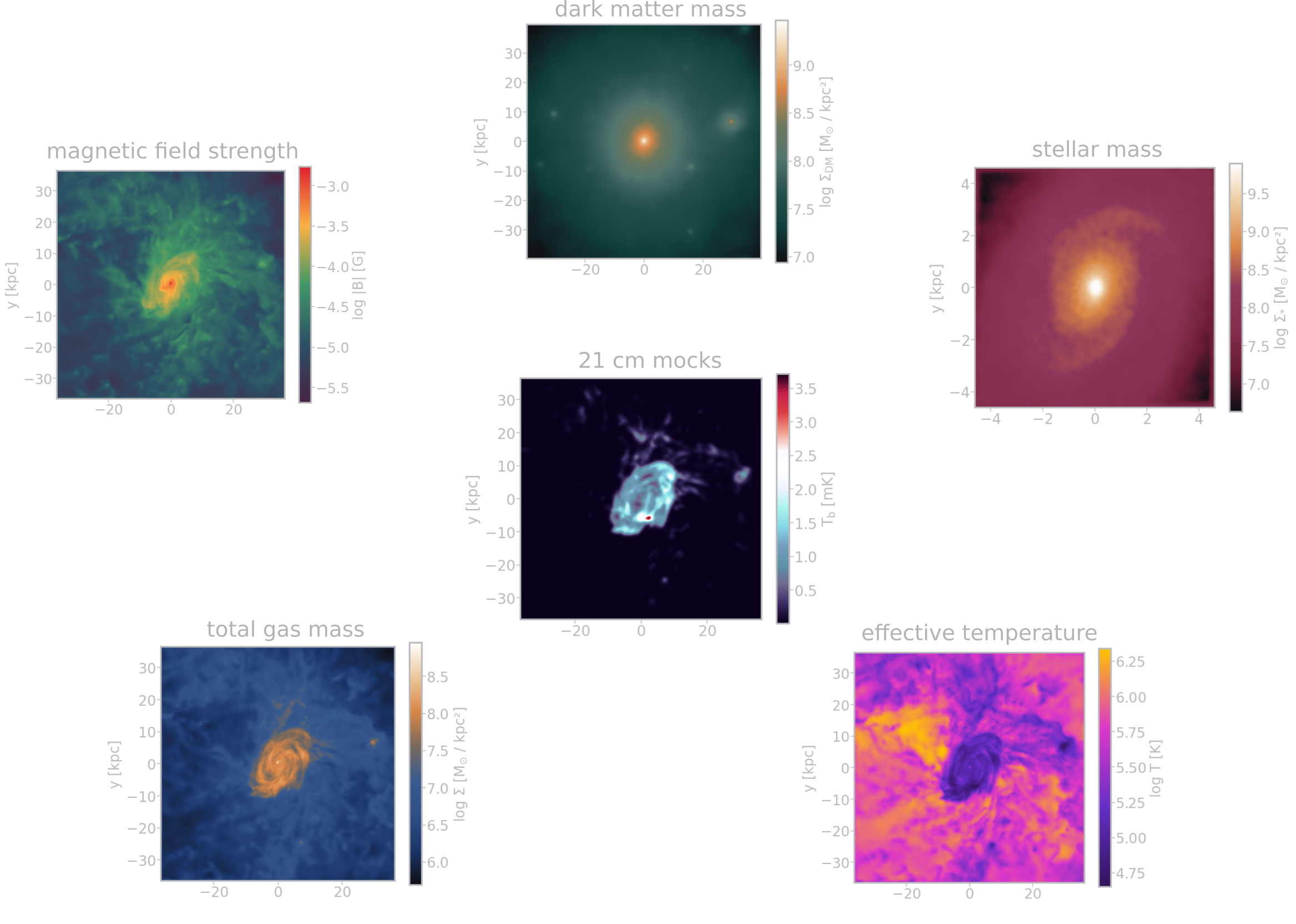
Dataset from IllustrisTNG
- projected TNG50-1 galaxies
- 6 domains: dark-matter, stars, gas,
HI, temperature, magnetic field- 21cm mocks following
Villaescusa-Navarro et al. (2018) - Karabo mock upgrade coming soon
- 21cm mocks following
- ∼ 2'000 galaxies, 6 snapshots,
5 rotations in 3D, ∼ 360'000 images - each galaxy \(\ge\) 10'000 particles
- scale: 2 baryonic half-mass radii
Generative Deep Learning
- Image-to-image translation solves the inverse problem:
\( \color{#f48193}{y} = A\color{#81f4a9}{x} + b \) - in Bayesian terms: \( p(\color{#81f4a9}{x}|\color{#f48193}{y}) \propto p(\color{#f48193}{y}|\color{#81f4a9}{x}) \,\, p(\color{#81f4a9}{x}) \)
- \( p(\color{#f48193}{y}|\color{#81f4a9}{x}) \) is the data likelihood including the physics
- \( p(\color{#81f4a9}{x}) \) is our prior knowledge on the solution.
- MAP solution: \( \hat{x} = \arg \max_{x} \log p(\color{#f48193}{y}|\color{#81f4a9}{x}) + \log p(\color{#81f4a9}{x}) \)
- explicitly sampling from the posterior distribution is difficult and expensive!
Generative Deep Learning architectures
Benchmark of generative models we're investigating:
- cGANs: implicit data likelihood (cf. one of my previous talk)
- Denoising Diffusion Probabilistic Models (DDPMs):
learns to collapse Gaussians into posterior - Inversion by Direct Iteration (InDI) models: similar to DDPMs,
but more efficient at inference - Score-based diffusion models (SDMs): promising results,
score gives direct access to the posterior likelihoods - Diffusion Mamba: the latest and greatest?
Generative Deep Learning architectures
- cGANs: implicit data likelihood (cf. one of my previous talk)
- Denoising Diffusion Probabilistic Models (DDPMs):
learns to collapse Gaussians into posterior
- Inversion by Direct Iteration (InDI) models: similar to DDPMs,
but more efficient at inference - Score-based diffusion models (SDMs): promising results,
score gives direct access to the posterior likelihoods - Diffusion Mamba: the latest and greatest?
cGANs
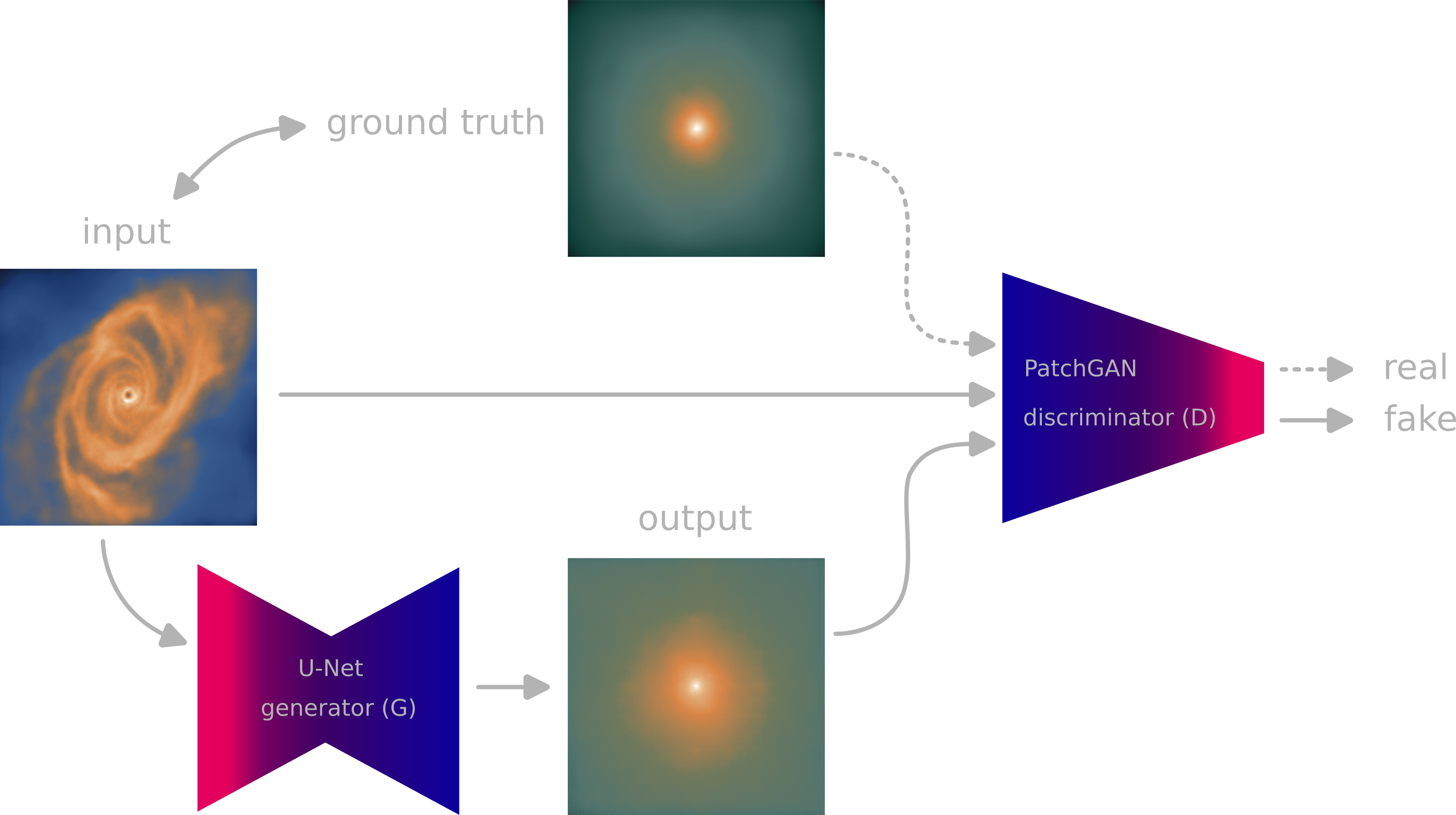
Figure 5: pix2pix scheme
DDPM

Main component: U-Net
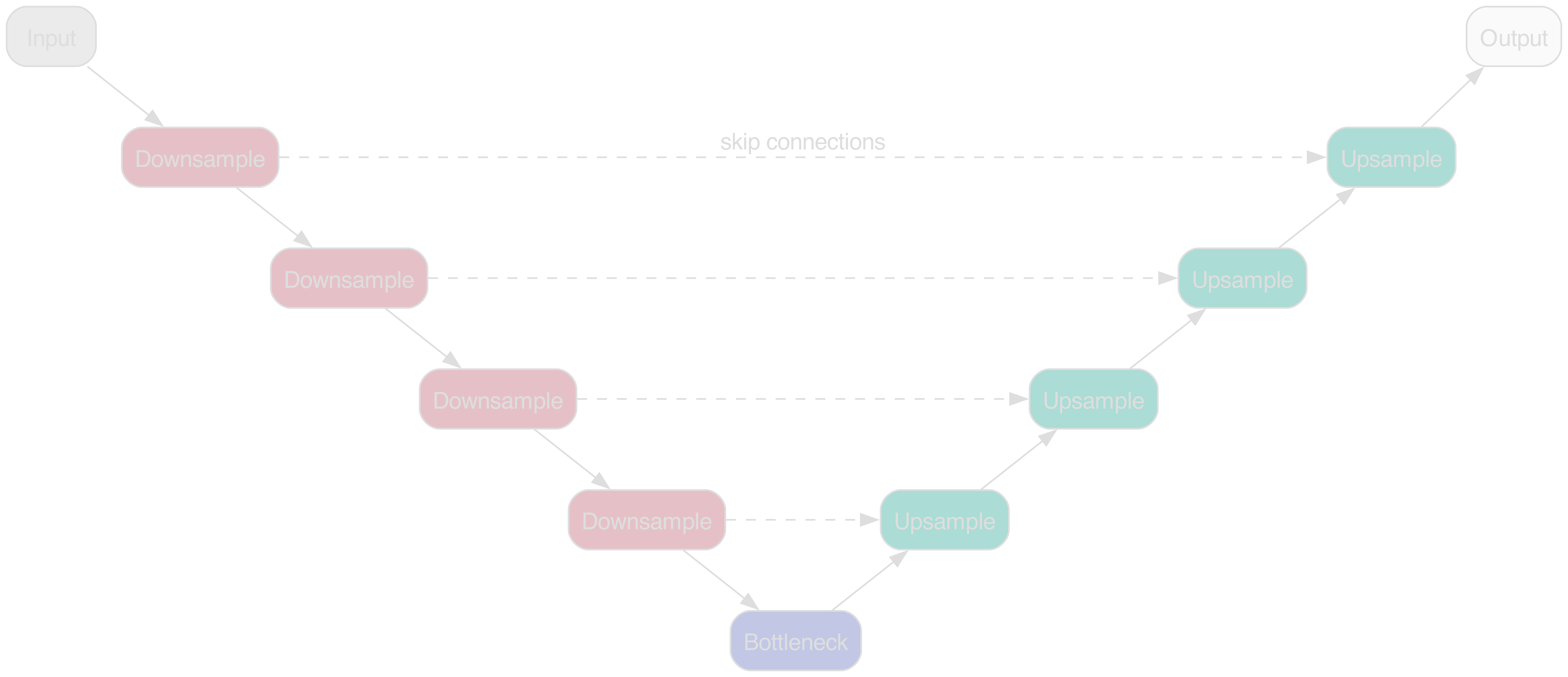
Figure 6: U-Net following Ronneberger et al. (2015)
Essential changes to U-Net blocks
"Attention is (almost) all you need!"
- for better feature selection

Results
- all evaluated on a hold-out set
- still somewhat preliminary…
Gas ⟶ DM: Massive halo

Figure 7: Input

Figure 8: Output (pix2pix with Attention U-Net)
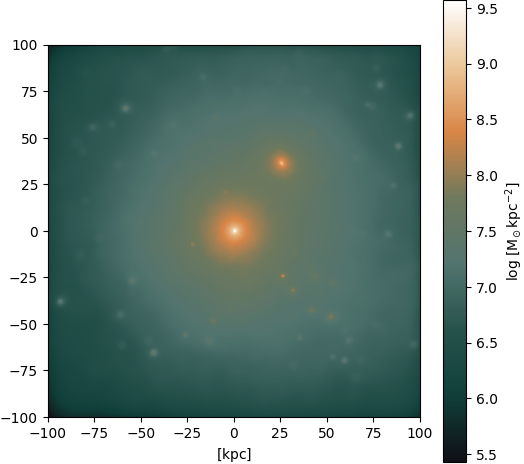
Figure 9: Ground truth
Gas ⟶ DM: Spiral galaxy
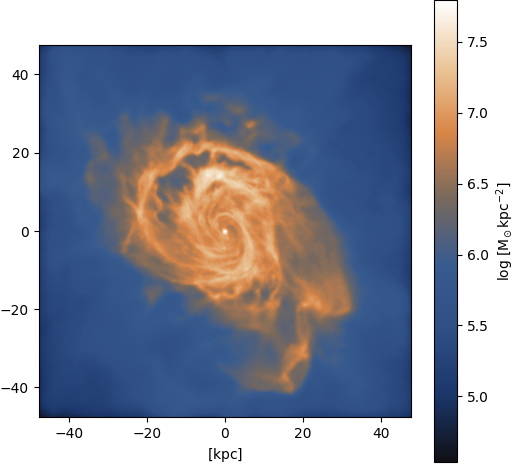
Figure 10: Input

Figure 11: Output (pix2pix with Attention U-Net)

Figure 12: Ground truth
Gas ⟶ DM: Merger

Figure 13: Input

Figure 14: Output (pix2pix with Attention U-Net)

Figure 15: Ground truth
Profiles of DM column density
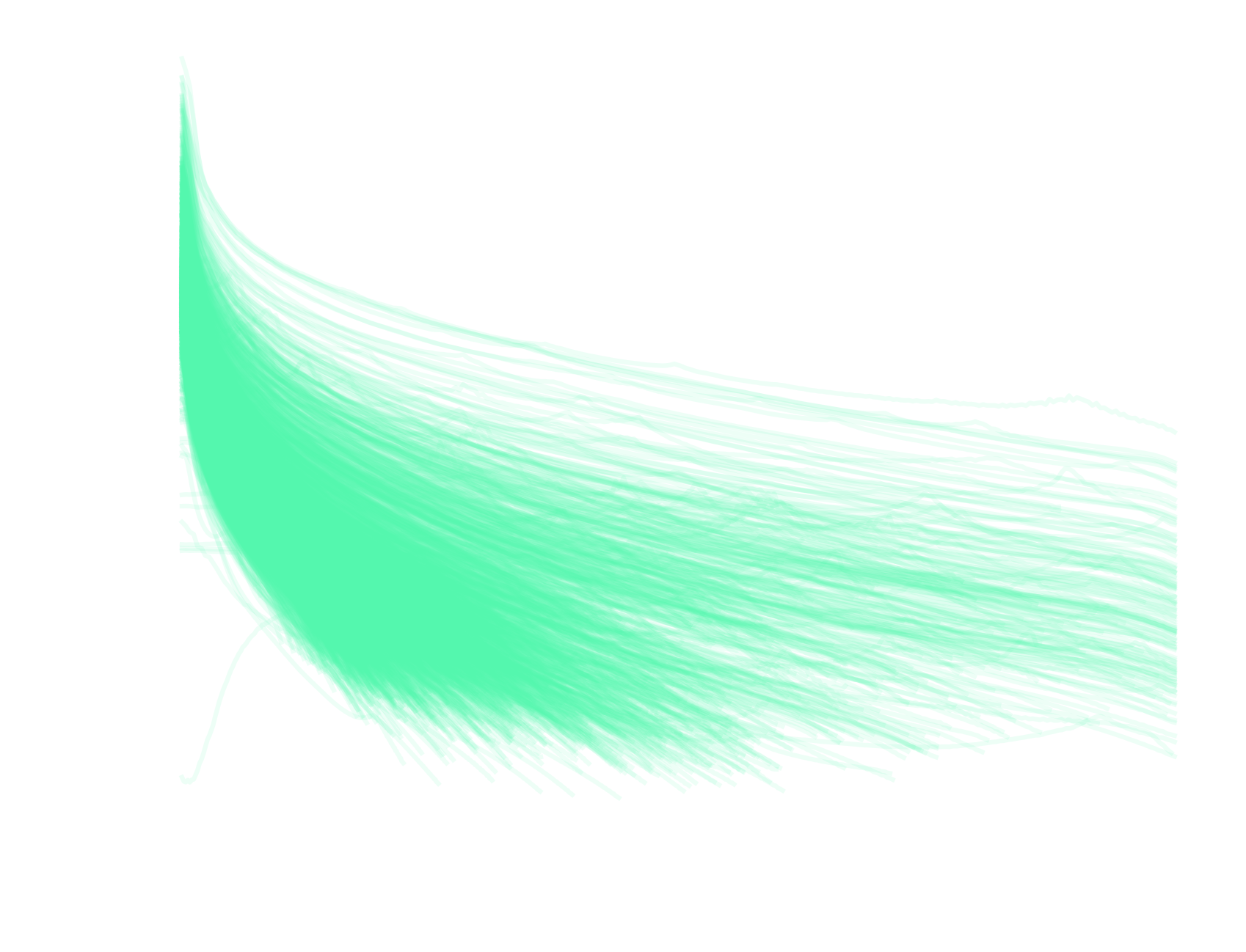
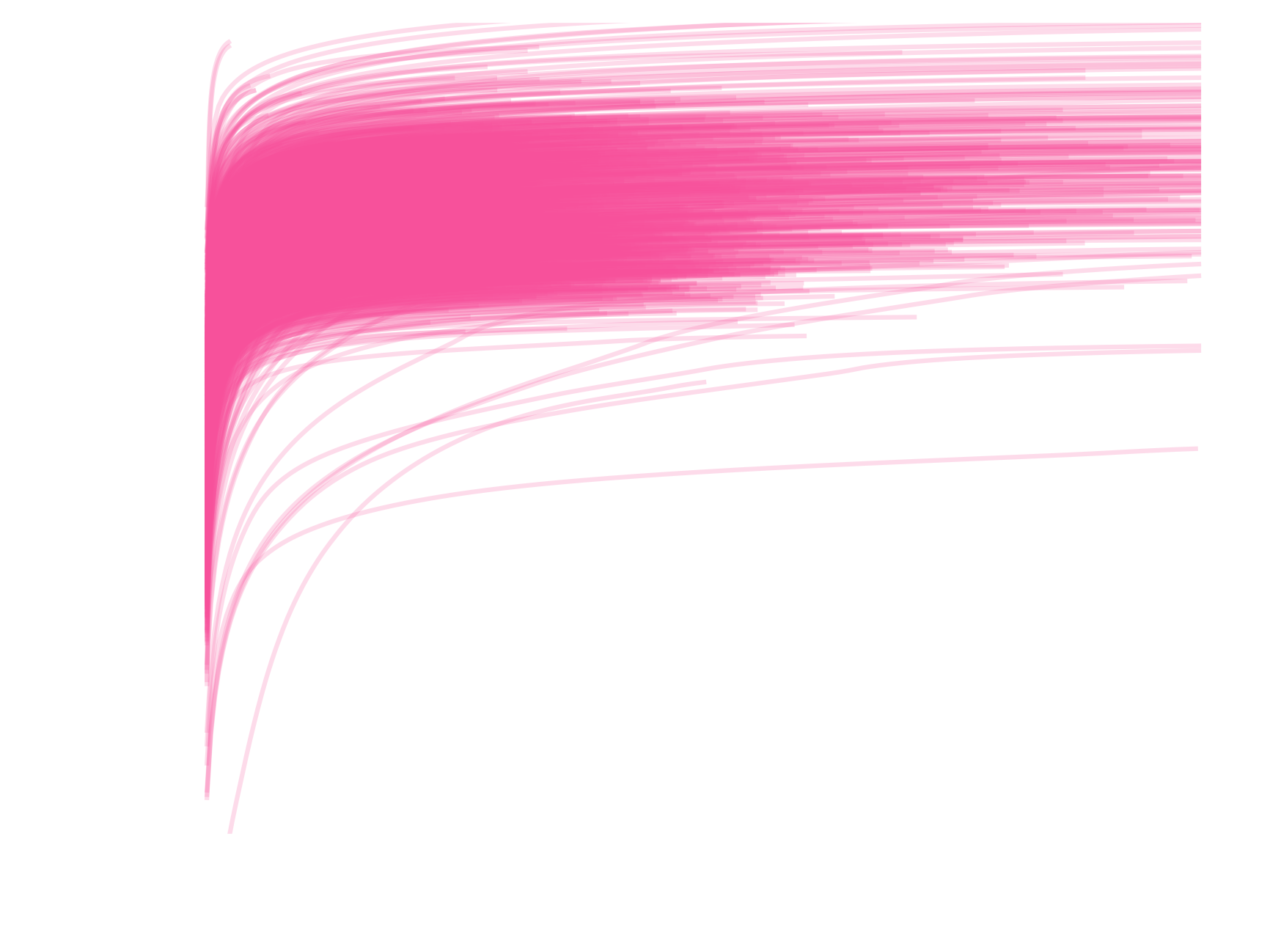
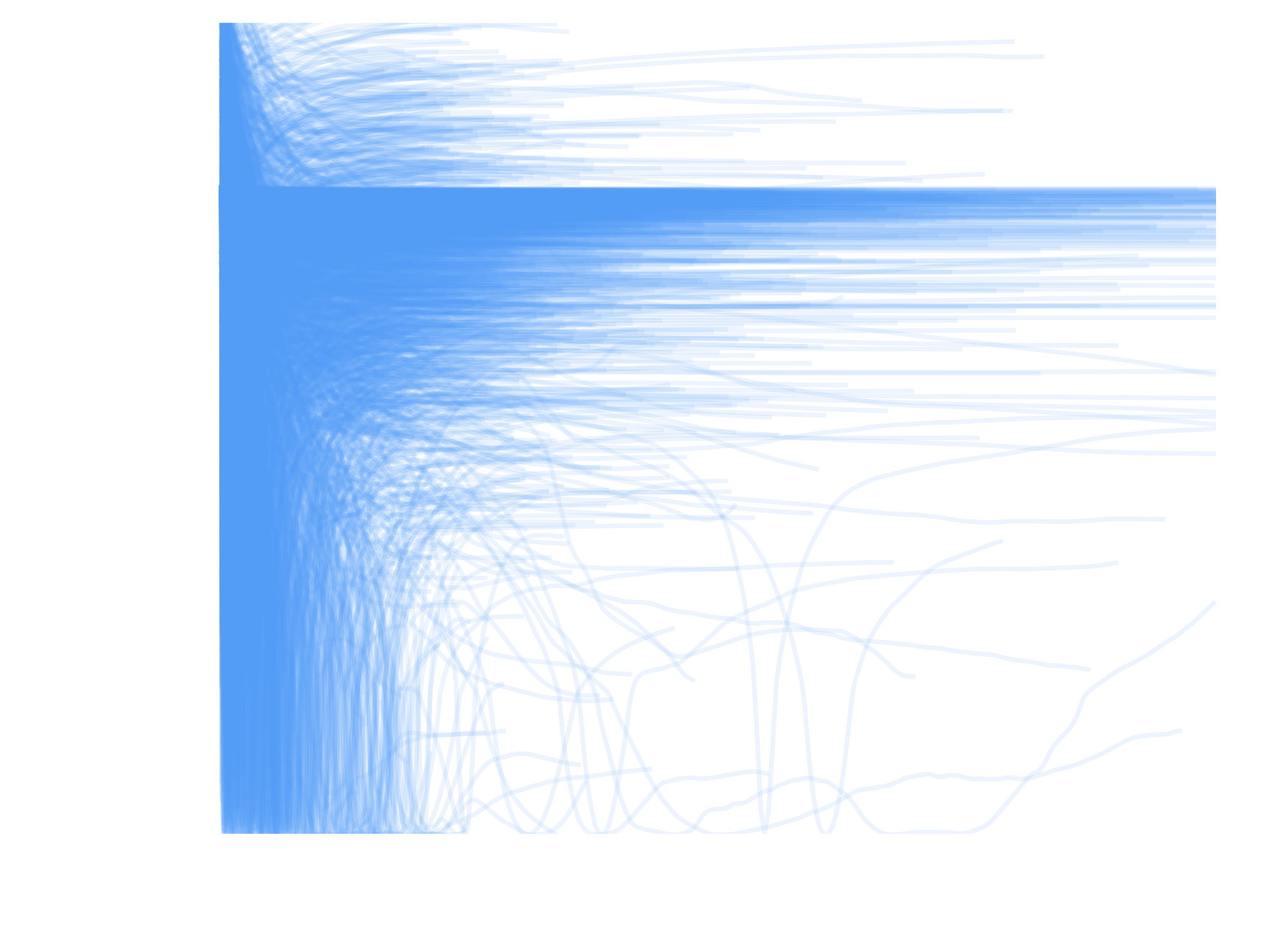
Profile residuals

Gas ⟶ stars: High turbulence
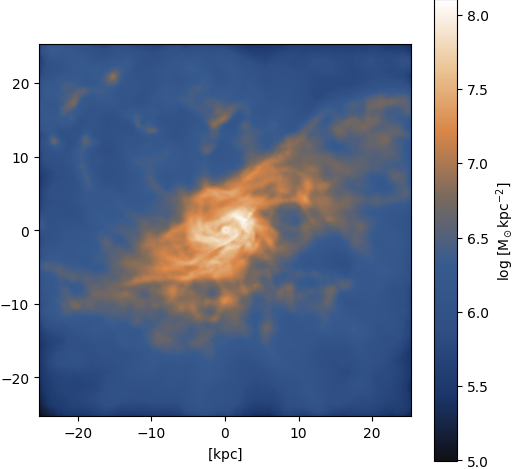
Figure 16: Input
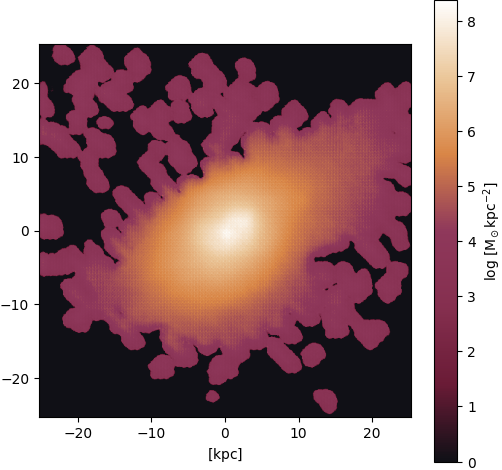
Figure 17: Output (pix2pix with Attention U-Net)
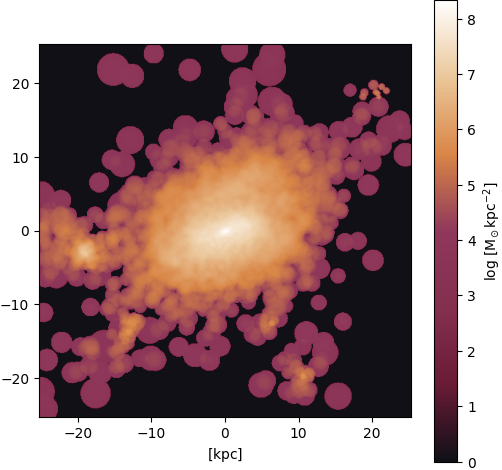
Figure 18: Ground truth
Gas ⟶ stars: Mergers
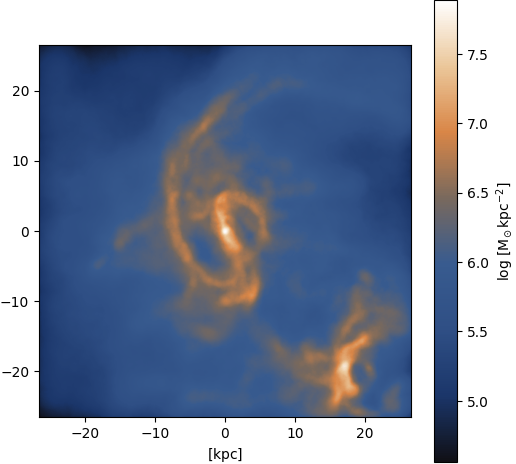
Figure 19: Input
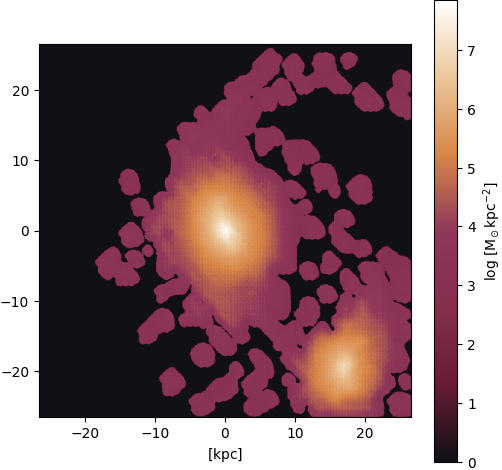
Figure 20: Output (pix2pix with Attention U-Net)
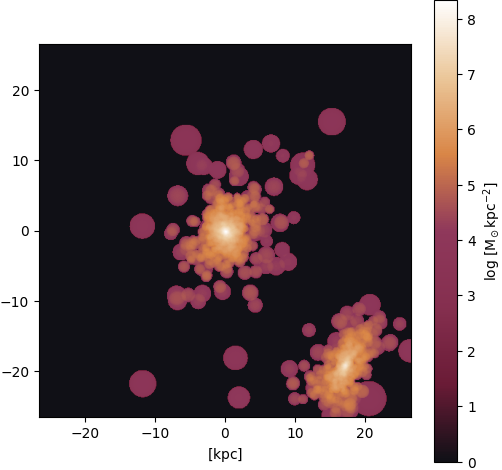
Figure 21: Ground truth
Gas ⟶ stars: Irregular shape
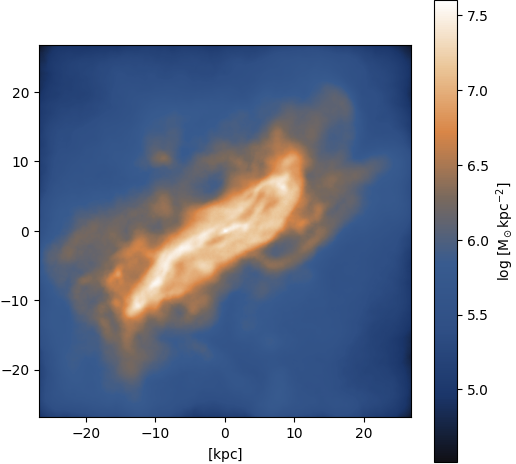
Figure 22: Input
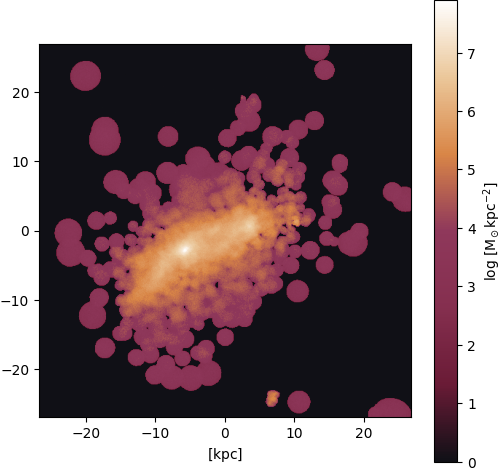
Figure 23: Output (standard DDPM)
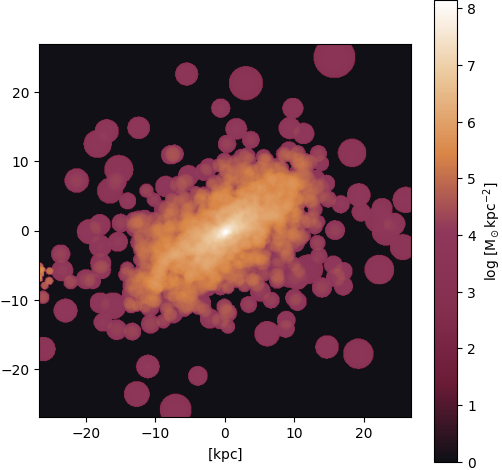
Figure 24: Ground truth
"Abundance matching"
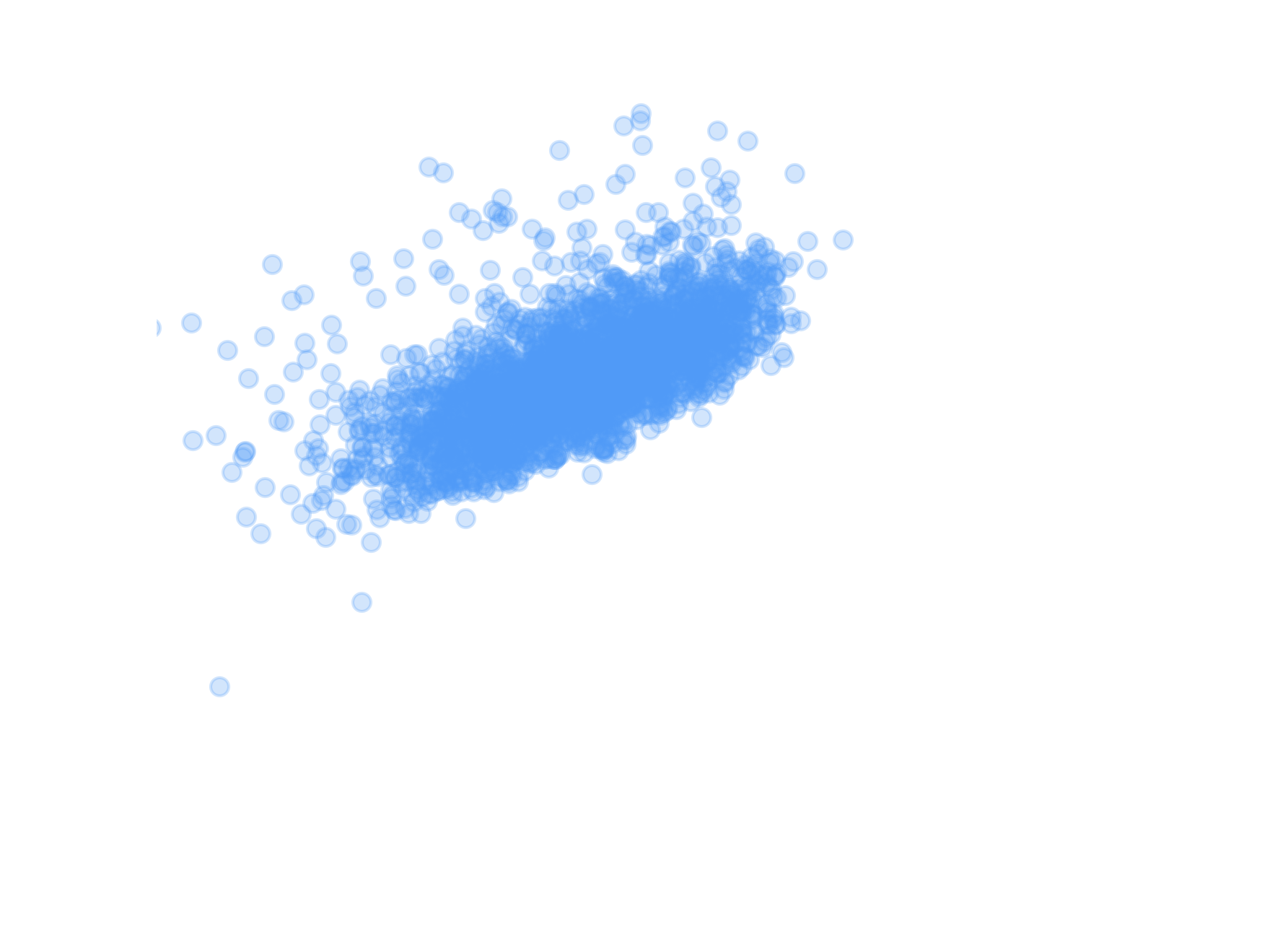
Figure 25: model using pix2pix+Attention
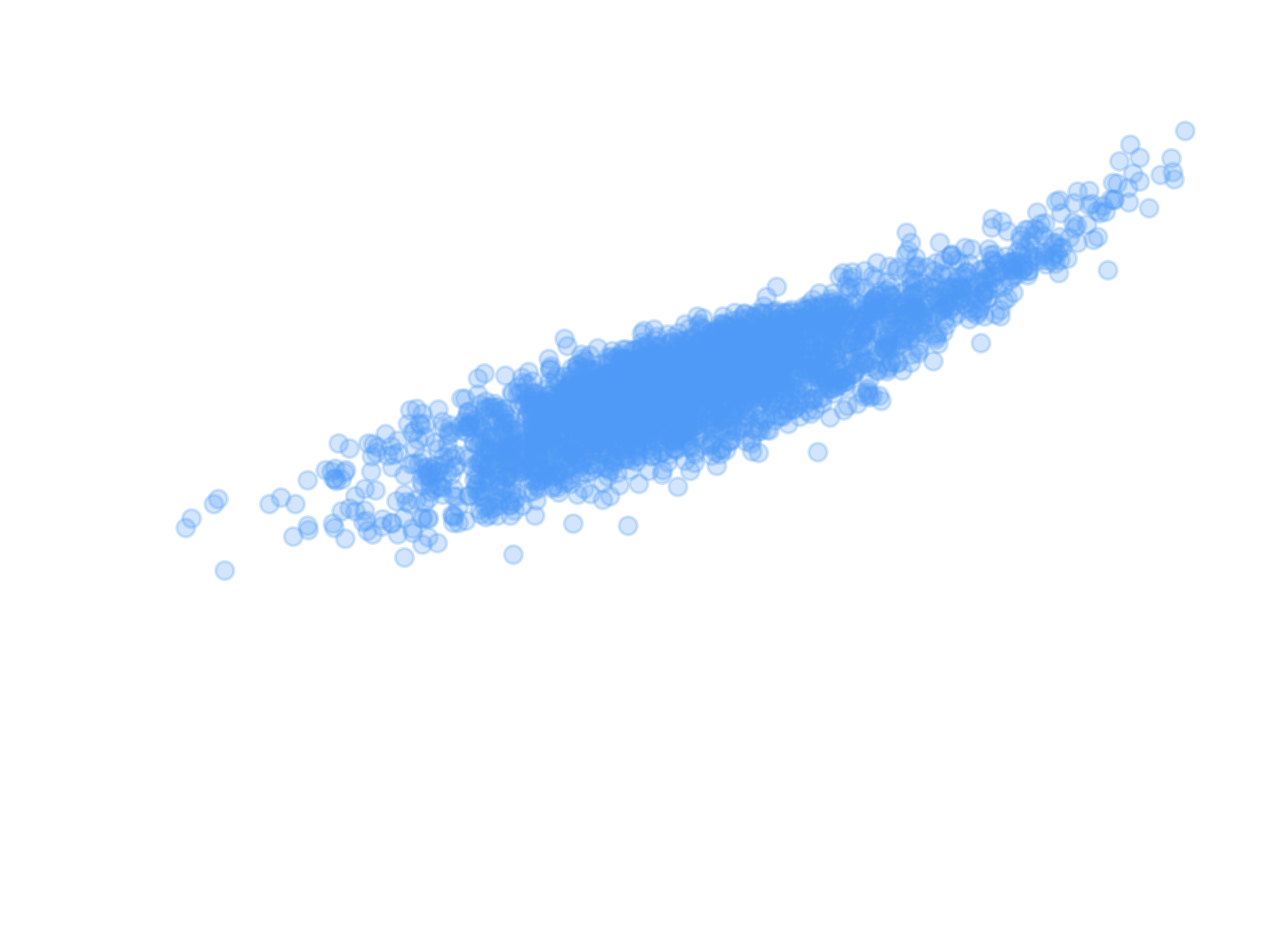
Figure 26: data
Gas ⟶ HI
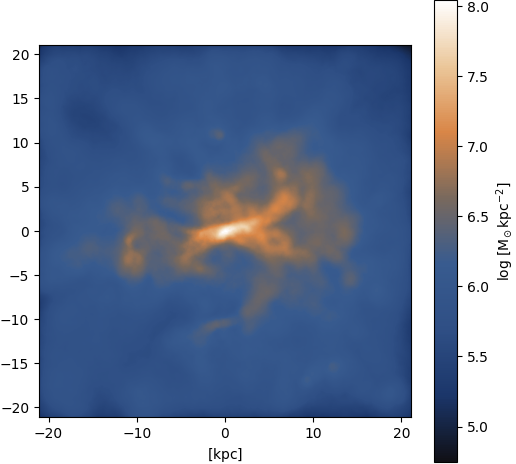
Figure 27: Input

Figure 28: Output (pix2pix with Attention U-Net)
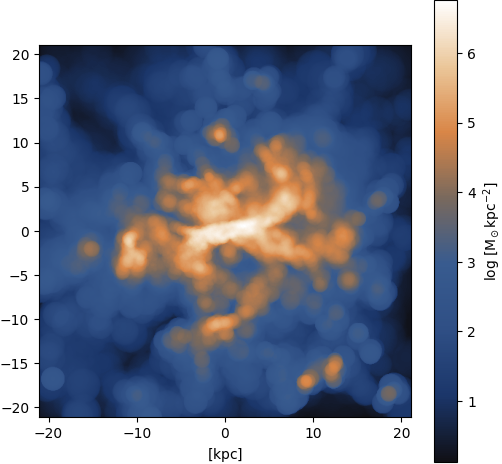
Figure 29: Ground truth
Gas ⟶ HI: Massive halo

Figure 30: Input
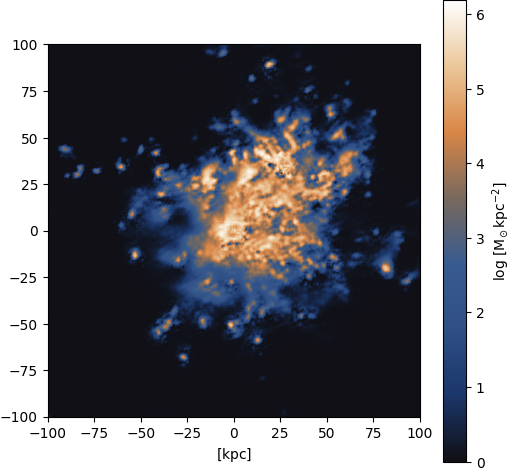
Figure 31: Output (pix2pix with Attention U-Net)
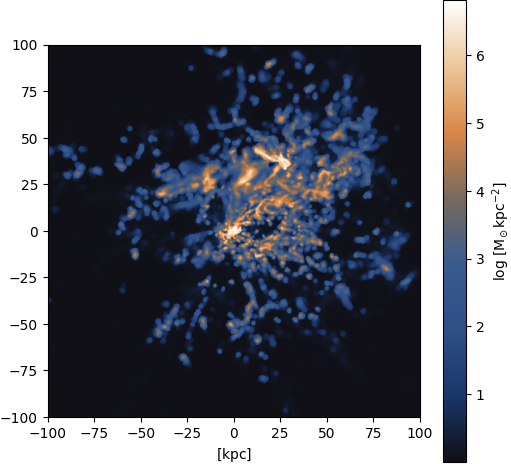
Figure 32: Ground truth
Profile residuals
Gas ⟶ B-field:

Figure 33: Input

Figure 34: Output (pix2pix with Attention U-Net)

Figure 35: Ground truth
Next steps
- paper in prep. (stay tuned)
- test more architectures
- improve observation mocks using Karabo
- analogue with point clouds in 3D
- problem: scaling to larger clouds
Contact
Email: philipp.denzel@zhaw.ch
References
- simulations: IllustrisTNG project
- SKA-MID simulation: Coogan et al. (2023)
- 21cm mocks: Villaescusa-Navarro et al. (2018)
- cGAN: Isola et al. (2016)
- DDPM: Ho et al. (2020)
- InDI: Delbracio & Milanfar (2023)
- SDM: Song et al. (2021)
- DiM: Teng et al. (2024)